User
Do you know the Royal Game of Ur?
ChatGPT
Yes, I do! The Royal Game of Ur is an ancient board game that dates back to Mesopotamia, roughly 4,500 years ago. It was discovered in the Royal Tombs of Ur in Iraq in the 1920s. The game involves two players who race their pieces across a board by rolling dice or throwing sticks with marked sides. It’s a race game, but some of the rules are still a bit unclear due to gaps in historical records. Despite that, it’s fascinating to see how this ancient game has similarities to some modern board games!
User
Can you create a strategy that could be used by a computer to play this game against a human?
ChatGPT
Creating a strategy for a computer to play the Royal Game of Ur involves a few key components:
Move Generation:
The computer needs to be programmed to understand the rules of the game and generate all possible moves for a given board position.
Evaluation Function
Develop an evaluation function that assesses the strength of a given board position. Factors might include the number of pieces in play, their positions on the board (especially in the last section before reaching home), and potential threats from the opponent.
Minimax Algorithm
Implement a search algorithm like Minimax with alpha-beta pruning to explore the game tree and select the best move based on the evaluation function.
Game State Representation
Create a data structure that represents the game board and allows the computer to efficiently manipulate and analyze the board state.
Learning from Experience
Consider using machine learning techniques or reinforcement learning to improve the computer’s gameplay by learning from previous games or simulations.
It’s essential to iterate and refine the strategy through testing and playing against different opponents to improve its effectiveness. Additionally, since the game has some ambiguities in its rules, the strategy might need adjustments or interpretations to handle these situations.
Would you like a more detailed breakdown of any of these components?
User
Yes, please.
ChatGPT
Let’s break down the steps to create a strategy for a computer to play the Royal Game of Ur against a human:
Move Generation:
Define the rules of the game: Understand how pieces move, capture opponents, and the special rules (like the use of the dice or sticks).
Create a function to generate all legal moves from a given board position.
Implement logic to handle special moves or situations, such as when a player gets a second turn after a roll.
Evaluation Function:
Design a function that evaluates the strength of a given board position for the computer player.
Consider factors like the number of pieces in play, their positions on the board (especially closer to home), safety of pieces, and potential captures.
Minimax Algorithm:
Implement the Minimax algorithm to search through the game tree.
Utilize alpha-beta pruning to improve the efficiency of the search.
Set a depth limit for the search tree to manage computational resources.
Game State Representation:
Create a data structure to represent the game board and the pieces.
Develop methods to update the board based on moves and maintain the board state efficiently.
Learning from Experience:
Consider implementing machine learning techniques:
Reinforcement learning: Allow the computer to learn from playing against itself or by observing human games.
Use neural networks to enhance the evaluation function by learning patterns from game positions.
Testing and Refinement:
Test the computer’s gameplay against different opponents, including human players and possibly other AI implementations.
Refine the strategy based on the results and feedback, adjusting the evaluation function or search algorithm as needed.
The strategy’s success may also depend on how well the rules and possible ambiguities are handled. Adapting to these variations or uncertainties could be crucial for an effective AI player.
Would you like a specific example or further details on any of these steps?
User
Further details on Move Generation
ChatGPT
Absolutely! Move generation is a critical aspect of programming an AI for the Royal Game of Ur. Here’s a more detailed breakdown:
Understanding the Rules:
Define how pieces move: In the Royal Game of Ur, pieces move along the board based on the outcome of rolling dice or throwing marked sticks. Understand how each roll or stick throw translates to moving pieces on the board.
Implement rules for safe zones and captures: Pieces can be captured by landing on opponent’s pieces unless they are in designated safe zones.
Consider special rules: For instance, earning an extra turn after a specific outcome or capturing an opponent’s piece.
Legal Move Generation:
Create a function that, given a board state and the outcome of the dice/sticks, generates all legal moves for the computer player.
Identify available pieces for movement: Determine which pieces can be moved based on the roll and the current board configuration.
Implement logic for safe zones and captures: Ensure the moves generated abide by the rules regarding safe zones and captures. Pieces in safe zones might have restrictions on movement.
Consider rules for winning: Implement logic to recognize when a player has reached the end of the board and won the game.
Handling Ambiguities:
Account for uncertain or ambiguous rules: The Royal Game of Ur has some ambiguities due to incomplete historical records. Your program might need to make assumptions or use interpretations for these situations.
Provide flexibility in move generation: Develop the code to handle unexpected or unclear scenarios during move generation.
Efficiency and Optimization:
Optimize move generation for efficiency: Aim for an algorithm that can quickly compute legal moves, especially as the game progresses and the board state becomes more complex.
Use data structures wisely: Represent the board and pieces in a way that allows for efficient move generation and evaluation.
Testing move generation thoroughly is crucial. Simulate various game scenarios, including edge cases and ambiguous situations, to ensure the AI behaves as expected. Adjust and refine the move generation logic based on these tests.
Would you like a specific code snippet or further details on any particular aspect of move generation?
User
Specific code snippet in C#
ChatGPT
Sure, here’s a simplified example of how you might generate legal moves for the Royal Game of Ur in C#:
// Define the board and pieces
enum Player { None, Player1, Player2 } // Represents empty, player 1, and player 2 pieces
int[] board = new int[14]; // Assuming a linear board with 14 spaces
// Function to generate legal moves for a player based on dice roll
List<int> GenerateLegalMoves(int[] board, Player currentPlayer, int diceRoll)
{
List<int> legalMoves = new List<int>();
// Logic to determine available pieces for the current player
List<int> playerPieces = new List<int>();
for (int i = 0; i < board.Length; i++)
{
if (board[i] == (int)currentPlayer)
{
playerPieces.Add(i);
}
}
// Generate moves for each piece based on the dice roll
foreach (int piece in playerPieces)
{
int destination = piece + diceRoll;
// Check if the destination is within bounds of the board
if (destination < board.Length)
{
// Check if the destination is a safe zone or empty
if (IsSafeZone(destination) || board[destination] == (int)Player.None)
{
legalMoves.Add(destination);
}
else
{
// Handle capture logic here if the destination is opponent's piece
// Implement capture rules based on the game's mechanics
// For example, capturing opponent's piece by moving onto it
// Add the capturing move to legalMoves if applicable
}
}
// Handle logic for reaching the end of the board and winning the game
// Add winning moves to legalMoves if applicable
}
return legalMoves;
}
bool IsSafeZone(int position)
{
// Implement logic to determine if a position is a safe zone
// Return true if the position is a safe zone, false otherwise
// Example:
// if (position == 3 || position == 7 || position == 12) return true;
// else return false;
}
This code provides a basic structure to generate legal moves for a given player based on a dice roll. It checks the available pieces, determines possible destinations based on the roll, and considers safe zones or empty spaces for potential moves.
Note: This code doesn’t cover all game rules, captures, or winning conditions. You’ll need to expand on this logic to encompass the complete rules of the Royal Game of Ur and handle more complex scenarios, including captures and winning conditions. Additionally, it assumes a linear board representation and may require adjustments for other board layouts.
User
More detailed breakdown of Evaluation Function
ChatGPT
Sure, let’s delve deeper into creating an evaluation function for the Royal Game of Ur. A good evaluation function assesses the current board state and assigns a score that represents the desirability of that state for the AI player. Here’s a more detailed breakdown:
Piece Count and Position:
Piece Count: Evaluate the number of pieces for both players. Generally, having more pieces on the board can be advantageous as it provides more mobility and options.
Piece Position: Consider the position of pieces, especially those closer to home. Pieces nearing the goal or in safe zones might contribute positively to the evaluation score.
Mobility:
Number of Available Moves: Evaluate the number of legal moves the AI player has from the current board state. Having more available moves can be advantageous.
Goal Proximity:
Pieces Near Goal: Determine the number of pieces close to reaching the goal. Pieces closer to the goal might receive a higher evaluation score.
Safety and Threats:
Safe Zones: Assess the safety of pieces in safe zones. Pieces in safe zones might be valued more positively due to their protected status.
Potential Captures: Evaluate potential captures by considering opponent pieces that could be captured in the next few moves.
Winning Conditions:
Winning Position: Assign a high score if the AI player is close to winning or has reached a winning position. Winning should have a significantly higher score than any other state.
Tuning Weights:
Adjust weights for different factors based on their relative importance. For example, the proximity to the goal might be more critical than the number of pieces on the board.
Function Implementation:
Combine these factors into an evaluation function that computes a score for a given board state. The function should take the current board state as input and output a numerical score representing the desirability of that state for the AI player.
Here’s a basic example integrating some of these factors into an evaluation function:
int EvaluateBoard(int[] board, Player currentPlayer)
{
int playerPiecesCount = 0;
int playerPiecesNearGoal = 0;
// Count the number of player pieces on the board and their positions
for (int i = 0; i < board.Length; i++)
{
if (board[i] == (int)currentPlayer)
{
playerPiecesCount++;
if (IsGoalProximity(i)) // Implement function to check proximity to goal
{
playerPiecesNearGoal++;
}
}
}
// Evaluate the board state based on piece count and goal proximity
int score = 100 * playerPiecesCount;
score += 50 * playerPiecesNearGoal;
return score;
}
This is a basic example focusing on piece count and proximity to the goal. Depending on the game’s intricacies and strategies, you may need to incorporate additional factors or fine-tune the evaluation function to make it more accurate and reflective of the game’s dynamics.
User
Code snippet for Evaluation Function in C#
ChatGPT
Certainly! Designing an evaluation function for the Royal Game of Ur involves assessing the board state to determine how advantageous it is for a player. Here’s a basic example of an evaluation function in C#:
// Evaluate the board state and return a score for the current player
int EvaluateBoard(int[] board, Player currentPlayer)
{
int playerPiecesCount = 0;
int opponentPiecesCount = 0;
int playerPiecesInGoal = 0;
int opponentPiecesInGoal = 0;
// Count the number of player and opponent pieces on the board
for (int i = 0; i < board.Length; i++)
{
if (board[i] == (int)currentPlayer)
{
playerPiecesCount++;
if (IsGoalPosition(i))
{
playerPiecesInGoal++;
}
}
else if (board[i] != (int)Player.None)
{
opponentPiecesCount++;
if (IsGoalPosition(i))
{
opponentPiecesInGoal++;
}
}
}
// Evaluate the board state based on piece count and positions
int score = 100 * (playerPiecesCount - opponentPiecesCount);
score += 50 * (playerPiecesInGoal - opponentPiecesInGoal);
return score;
}
bool IsGoalPosition(int position)
{
// Implement logic to determine if a position is a goal position
// Return true if the position is a goal position, false otherwise
// Example:
// if (position == 13) return true; // Assuming position 13 is the goal for player 1
// else return false;
}
This basic evaluation function calculates a score based on the number of pieces on the board for the current player and the opponent, as well as the number of pieces in goal positions for each player. Adjust the weights and factors in the evaluation function to better reflect the game’s dynamics and strategies.
Remember, this is a simple evaluation function and doesn’t capture all aspects of the game state. You might want to consider additional factors such as piece mobility, potential captures, or piece arrangements to improve the evaluation’s accuracy.
Feel free to enhance this function by considering more nuanced features of the game state to make the AI’s evaluation more sophisticated.
User
More detailed breakdown of Minimax Algorithm
ChatGPT
Certainly! The Minimax algorithm aims to search through the game tree to determine the best move for a player while considering the opponent’s moves. Here’s a more detailed breakdown of how the Minimax algorithm works:
Tree Traversal:
Root Node: The algorithm starts at the root node, representing the current state of the game.
Expanding Nodes: It generates all possible moves for the current player from the root node, creating child nodes for each possible move.
Depth Limit: Minimax explores the game tree up to a certain depth or until a terminal state (end of the game) is reached.
Evaluation:
Leaf Nodes: When the algorithm reaches a leaf node (either a terminal state or the maximum depth), it evaluates the node using an evaluation function.
Score Calculation: The evaluation function assigns a score to the terminal nodes, representing the desirability of that game state for the current player.
Backtracking:
Maximizing and Minimizing Layers: Minimax alternates between maximizing (AI player’s turn) and minimizing (opponent’s turn) layers of the tree.
Maximizing Player (AI): At maximizing layers, the AI player chooses the move that maximizes its score (chooses the child node with the highest score).
Minimizing Player (Opponent): At minimizing layers, the opponent chooses the move that minimizes the AI player’s score (chooses the child node with the lowest score).
Alpha-Beta Pruning:
Optimization Technique: Alpha-beta pruning is used to reduce the number of nodes evaluated.
Pruning Unnecessary Nodes: It eliminates nodes that won’t affect the final decision by maintaining alpha (the best value found so far for the maximizing player) and beta (the best value found so far for the minimizing player) values.
Termination and Decision:
Terminal Nodes: If the algorithm reaches a terminal node (end of the game), it returns the node’s evaluation score.
Decision: Once the tree has been traversed to the specified depth or terminal nodes, Minimax selects the move that leads to the highest evaluated score for the AI player.
Here’s a basic structure of Minimax algorithm in pseudocode:
function minimax(node, depth, maximizingPlayer):
if depth = 0 or node is a terminal node:
return the heuristic value of node
if maximizingPlayer:
bestValue = negative infinity
for each child of node:
value = minimax(child, depth - 1, false)
bestValue = max(bestValue, value)
return bestValue
else:
bestValue = positive infinity
for each child of node:
value = minimax(child, depth - 1, true)
bestValue = min(bestValue, value)
return bestValue
This pseudocode demonstrates the basic structure of Minimax, alternating between maximizing and minimizing layers, evaluating nodes using a heuristic function, and recursively traversing the game tree to determine the optimal move for the AI player. Incorporating alpha-beta pruning further enhances the efficiency of this algorithm by eliminating unnecessary branches in the game tree.
User
Code snippet for Minimax Algorithm in C#
ChatGPT
Certainly! Implementing the Minimax algorithm involves searching through the game tree to determine the best move for the current player while considering the opponent’s possible moves. Here’s a basic example of Minimax in C# for the Royal Game of Ur:
// Define a class to represent the game state
class GameState
{
public int[] Board { get; set; }
public Player CurrentPlayer { get; set; }
// Add any other necessary properties to represent the game state
}
// Minimax algorithm with alpha-beta pruning
int Minimax(GameState gameState, int depth, int alpha, int beta, bool maximizingPlayer)
{
if (depth == 0 /*or game is over*/)
{
return EvaluateBoard(gameState.Board, gameState.CurrentPlayer);
}
if (maximizingPlayer)
{
int maxEval = int.MinValue;
List<int> legalMoves = GenerateLegalMoves(gameState.Board, gameState.CurrentPlayer, /*dice roll*/);
foreach (int move in legalMoves)
{
// Create a new game state after making the move
GameState newGameState = /* Create a copy of gameState and apply the move */;
int eval = Minimax(newGameState, depth - 1, alpha, beta, false);
maxEval = Math.Max(maxEval, eval);
alpha = Math.Max(alpha, eval);
if (beta <= alpha)
{
break; // Beta cutoff
}
}
return maxEval;
}
else
{
int minEval = int.MaxValue;
List<int> legalMoves = GenerateLegalMoves(gameState.Board, /*opponent*/);
foreach (int move in legalMoves)
{
// Create a new game state after making the move
GameState newGameState = /* Create a copy of gameState and apply the move */;
int eval = Minimax(newGameState, depth - 1, alpha, beta, true);
minEval = Math.Min(minEval, eval);
beta = Math.Min(beta, eval);
if (beta <= alpha)
{
break; // Alpha cutoff
}
}
return minEval;
}
}
This code demonstrates the basic structure of the Minimax algorithm with alpha-beta pruning. You’ll need to integrate it with your existing codebase, including the game state representation, move generation, and evaluation function. Additionally, ensure that the functions for creating and applying moves, as well as checking the game state and terminal conditions, are correctly implemented within the algorithm.
This implementation assumes a recursive approach to explore the game tree, considering both maximizing and minimizing players and using alpha-beta pruning to improve efficiency by pruning branches that won’t affect the final decision.
Adapt this algorithm to fit the specifics of your game implementation and optimize it as needed for the Royal Game of Ur.
User
More detailed breakdown of Game State Representation
ChatGPT
Absolutely, a comprehensive game state representation is crucial for any AI implementation. For the Royal Game of Ur, a robust representation involves capturing various elements such as the board layout, player positions, and game status. Let’s break it down:
Board Representation:
Board Structure: Define the structure of the board. The Royal Game of Ur typically consists of a linear track with specific positions and safe zones.
Data Structure: Use an array, matrix, or another suitable data structure to represent the board. Each element might represent a space on the board, its state (empty, occupied by Player 1, Player 2, etc.), or its attributes (such as safe zones).
Initial State: Set up the initial positions of players’ pieces on the board.
Player Positions:
Player Pieces: Track the positions of each player’s pieces on the board.
Piece Status: Include information about the pieces’ status (e.g., in safe zones, on the main track, near the goal).
Game Status:
Current Player: Store information about whose turn it is in the game.
Dice or Stick Roll: Represent the outcome of the dice or stick roll, as this affects the available moves for the current player.
Game State Manipulation:
Move Validation: Implement functions to validate moves based on the current game state. Ensure that the moves adhere to the game rules.
Updating State: Create functions to update the game state based on valid moves made by players. This involves moving pieces, resolving captures, and determining game outcomes (win/loss/draw).
Representation Example (Pseudocode):
class GameState:
int[] board // Represents the game board
Player currentPlayer // Stores the current player
int diceRoll // Stores the outcome of the dice roll
GameState():
// Initialize the board and set the starting player
// Set up initial board positions, player pieces, and any other necessary details
bool isValidMove(int from, int to):
// Check if the move from 'from' to 'to' is valid based on game rules
// Return true if valid, false otherwise
void applyMove(int from, int to):
// Update the board and game state based on the move from 'from' to 'to'
// Move player pieces, handle captures, update dice roll, and switch players
// Other methods and properties as needed...
This example outlines a basic structure for the GameState class in pseudocode. It includes elements such as the board representation, player positions, methods for move validation, and updating the game state based on valid moves.
The actual implementation in C# would involve defining the data structures, implementing methods for validating and applying moves, and managing the game state transitions accurately according to the rules of the Royal Game of Ur.
User
Code snippet for Game State Representation in C#
ChatGPT
Certainly! The game state representation in C# should encapsulate the current state of the board and any other relevant information needed to track the game. Here’s a basic example:
class GameState
{
public enum Player { None, Player1, Player2 }
public int[] Board { get; private set; } // Representing the game board
public Player CurrentPlayer { get; private set; } // Current player
public GameState()
{
// Initialize the board and set the starting player
Board = new int[14]; // Assuming a linear board with 14 spaces
InitializeBoard(); // Function to set up the initial board state
CurrentPlayer = Player.Player1; // Start with Player 1
}
// Function to apply a move to the game state
public void ApplyMove(int from, int to)
{
// Implement logic to update the board based on the move
// Update the board array to reflect the move from 'from' to 'to'
// Adjust player turns or any other game state changes
}
// Other methods and properties as needed...
// Example method to initialize the board to the starting position
private void InitializeBoard()
{
// Implement initialization logic here
// Set up the board with player pieces at their starting positions
// For example:
// Board[0] = (int)Player.Player1; // Set Player 1's piece at position 0
// Board[13] = (int)Player.Player2; // Set Player 2's goal position at index 13
// ...
}
}
This GameState class represents the game state with a board array and a CurrentPlayer property to keep track of whose turn it is. You’d need to implement methods to update the board (ApplyMove) based on the moves made by players, handle win conditions, and perform other game-related operations.
The ApplyMove method would be responsible for updating the board according to the move made by a player. It should validate the move’s legality and update the board state accordingly.
This is a basic skeleton representation of the game state. Depending on your game’s complexity and requirements, you might need to expand this class to include more functionalities or additional properties/methods to manage the game state effectively.
User
More detailed breakdown of Learning from Experience
ChatGPT
Certainly! Implementing learning from experience typically involves reinforcement learning techniques such as Q-learning. Here’s a more detailed breakdown of how Q-learning can be applied to the Royal Game of Ur:
Q-Learning Components:
Q-Table:
State-Action Pairs: Create a table that maps state-action pairs to their respective Q-values. In the Royal Game of Ur, states might represent board configurations, and actions might represent possible moves.
Initialization: Initialize the Q-table with initial values (usually zeros) for all state-action pairs.
Exploration and Exploitation:
Exploration: During learning, the AI explores the game space by choosing actions based on exploration policies (like epsilon-greedy). This allows the AI to discover new strategies.
Exploitation: Over time, the AI exploits the learned information by choosing actions that maximize expected rewards based on the Q-values.
Reward System:
Immediate Rewards: Define the immediate rewards the AI receives for taking certain actions in specific states. For the Royal Game of Ur, rewards might be given for reaching the goal or capturing opponent pieces.
Delayed Rewards: Consider long-term rewards based on reaching terminal states (winning or losing the game).
Update Q-Values:
Q-Value Update Rule: Use the Q-learning update formula to adjust Q-values after each action taken.
Learning Rate (α): Determine the learning rate, which controls how much the new information overrides old information.
Discount Factor (γ): Choose the discount factor to balance immediate and future rewards.
Implementation Steps:
Initialize Q-Table:
Create a Q-table to store Q-values for state-action pairs.
Action Selection:
Use an exploration-exploitation strategy (like epsilon-greedy) to select actions based on the current state. Initially, prioritize exploration to populate the Q-table.
Perform Actions:
Based on the chosen action, apply the move in the game and observe the resulting state and immediate reward.
Update Q-Values:
Use the Q-learning update rule to adjust the Q-value for the chosen action and state based on the observed reward and the estimated future rewards.
Repeat and Learn:
Repeat the process for multiple iterations or episodes, allowing the AI to learn by updating Q-values through trial and error.
Example Pseudocode (Q-Learning):
Initialize Q-table Q(s, a) with zeros for all state-action pairs
For each episode:
Initialize state S
Repeat until game ends:
Choose action A from state S using epsilon-greedy policy
Take action A, observe new state S', and immediate reward R
Update Q-value for state-action pair based on the observed reward and future estimation:
Q(S, A) = (1 - α) * Q(S, A) + α * (R + γ * max(Q(S', a')))
Move to the next state S'
This pseudocode demonstrates the Q-learning process for the Royal Game of Ur. It outlines the steps of exploration, action selection, updating Q-values, and iterative learning through multiple episodes. Actual implementation involves translating these steps into code, managing the game state, and integrating Q-learning logic to train the AI to play the game effectively.
User
Code snippet for Learning from Experience in C#
ChatGPT
Implementing learning from experience, especially through machine learning or reinforcement learning, requires a more sophisticated approach and libraries to handle the learning process. Here’s a basic example using a simple Q-learning algorithm in C#:
class QLearning
{
// Define Q-table to store state-action values
private Dictionary<string, Dictionary<int, double>> qTable = new Dictionary<string, Dictionary<int, double>>();
// Function to update Q-values based on a state-action pair and a reward
public void UpdateQValue(string state, int action, double reward, string nextState, double learningRate, double discountFactor)
{
if (!qTable.ContainsKey(state))
{
qTable[state] = new Dictionary<int, double>();
}
if (!qTable.ContainsKey(nextState))
{
qTable[nextState] = new Dictionary<int, double>();
}
// Get the current Q-value for the state-action pair
double currentQValue = qTable[state].ContainsKey(action) ? qTable[state][action] : 0;
// Find the maximum Q-value for actions in the next state
double maxNextQValue = qTable[nextState].Values.Count > 0 ? qTable[nextState].Values.Max() : 0;
// Update Q-value using the Q-learning formula
double newQValue = currentQValue + learningRate * (reward + (discountFactor * maxNextQValue) - currentQValue);
qTable[state][action] = newQValue;
}
// Function to get the best action for a given state based on Q-values
public int GetBestAction(string state)
{
if (!qTable.ContainsKey(state) || qTable[state].Count == 0)
{
// Return a random action if state not found or Q-values are not available
return GetRandomAction();
}
// Get the action with the highest Q-value for the given state
return qTable[state].OrderByDescending(kv => kv.Value).First().Key;
}
// Function to perform exploration by selecting a random action
private int GetRandomAction()
{
// Implement logic to select a random action
// For example:
Random random = new Random();
return random.Next(/*number of possible actions*/);
}
}
This example demonstrates a basic Q-learning approach, where the QLearning class maintains a Q-table (as a dictionary) to store state-action values. The UpdateQValue method updates Q-values based on rewards received, and the GetBestAction method selects the best action for a given state based on Q-values.
For the Royal Game of Ur, you would need to define states, actions, rewards, and the learning process based on the game’s dynamics. States could represent board configurations, actions could represent possible moves, rewards could be based on winning/losing, and learning rates/discount factors could influence learning speed and future rewards.
Implementing machine learning for a game involves more complexities and nuances than this basic example, and you may need to adapt this to suit the specific requirements and intricacies of the Royal Game of Ur. Utilizing machine learning libraries or frameworks like ML.NET or Accord.NET can also streamline the implementation.
User
What would be the best way to represent the game board?
ChatGPT
In the Royal Game of Ur, the game board consists of a track with 20 spaces, some of which are shared between players, while others are safe zones or goal spaces. Representing this board accurately is essential for managing game state and facilitating AI decision-making. Here’s a recommended way to represent the game board:
Board Representation:
Array or List:
Use an array or list data structure to represent the 20 spaces on the game board. This structure allows easy indexing and manipulation of positions.
Assign different values or markers to represent various states of the spaces:
Player 1’s pieces
Player 2’s pieces
Shared spaces
Safe zones
Goal spaces
Board Layout:
Define the board layout in a linear track format, including shared spaces, safe zones, and goal spaces.
Assign specific indices to denote different sections of the board, ensuring accurate representation of the track layout.
Data Structure for Player Positions:
Use a separate data structure (e.g., an array or dictionary) to track each player’s piece positions on the board.
Store the positions of player pieces separately for easy access and manipulation.
Example (Pseudocode):
Here’s an example of how you might represent the game board and player positions in pseudocode:
class GameState:
int[] board // Represents the game board (20 spaces)
Dictionary<Player, List<int>> playerPositions // Stores positions of each player's pieces
GameState():
// Initialize the board and set the starting player
// Set up initial board positions, player pieces, safe zones, and goal spaces
bool isValidMove(int from, int to):
// Check if the move from 'from' to 'to' is valid based on game rules
// Return true if valid, false otherwise
void applyMove(int from, int to):
// Update the board and game state based on the move from 'from' to 'to'
// Move player pieces, handle captures, update dice roll, and switch players
// Other methods and properties as needed...
This representation uses an array to represent the game board and a dictionary (playerPositions) to track each player’s piece positions. The isValidMove and applyMove functions would manage move validation and game state transitions based on the chosen moves.
This approach allows for clear and efficient representation of the game board, facilitating easy tracking of player positions and manipulation of the game state during AI gameplay.
User
Both players would move through different indexes in the board array. How would you deal with that?
ChatGPT
Absolutely, the distinction between the tracks for each player in the Royal Game of Ur does require careful consideration in the board representation. Here’s an approach to handle this scenario:
Separation of Tracks:
Linear Representation:
Represent the board as a linear array or list, accommodating both players’ tracks.
Define the board layout considering the separate paths for each player within the array structure.
Player-Specific Markers:
Use distinct markers or values in the array to differentiate spaces for Player 1, Player 2, shared spaces, safe zones, and goal spaces.
Allocate specific sections of the array to represent each player’s track and shared spaces.
Player Position Tracking:
Maintain separate data structures (e.g., lists or indices) to track the positions of each player’s pieces within their respective tracks.
Update player positions accordingly based on the moves made during the game.
Revised Board Representation (Pseudocode):
class GameState:
int[] board // Represents the game board (linear track for both players)
List<int> player1Positions // Stores positions of Player 1's pieces
List<int> player2Positions // Stores positions of Player 2's pieces
GameState():
// Initialize the board and set the starting player
// Set up initial board positions, player pieces, safe zones, and goal spaces
bool isValidMove(int from, int to, Player currentPlayer):
// Check if the move from 'from' to 'to' is valid for the currentPlayer based on game rules
// Return true if valid, false otherwise
void applyMove(int from, int to, Player currentPlayer):
// Update the board and game state based on the move from 'from' to 'to' by currentPlayer
// Move player pieces, handle captures, update dice roll, and switch players
// Other methods and properties as needed...
This revised representation maintains a linear board array accommodating both players’ tracks. Separate player1Positions and player2Positions lists track the positions of each player’s pieces within their respective tracks.
The isValidMove and applyMove functions consider the current player making the move and validate/applying the move accordingly.
This approach allows the representation of the board to reflect both players’ tracks within a single array structure, enabling efficient management of positions and moves during gameplay.

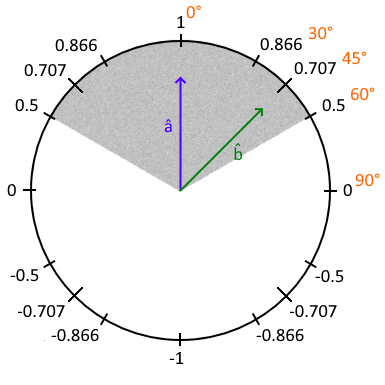
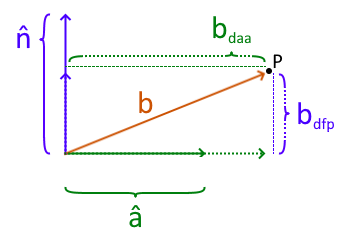
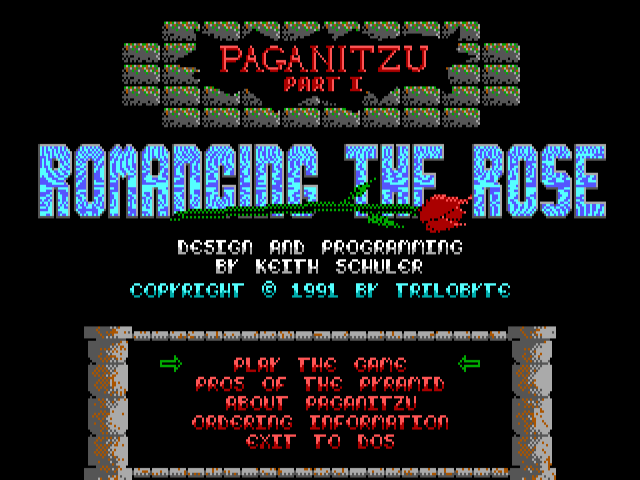 One of my most enjoyable hobbies is reverse engineering old 1980s/90s DOS games. This is very akin to an archeologist learning everything they can about a culture by examining dug up buildings, bones, artifacts, etc. The original source code for the game is not available. All I have is the executable and the data files that get installed with it. My job is to “excavate” that executable and all its data files, pick them apart and get them to reveal their secrets to me. Some of those data files may contain images used in the game, some audio, some information about the levels/maps… The executable contains the “logic” used to run the game probably. Things like what happens when an enemy touches the main player? How much does your score or health go down? What happens when your character dies?
One of my most enjoyable hobbies is reverse engineering old 1980s/90s DOS games. This is very akin to an archeologist learning everything they can about a culture by examining dug up buildings, bones, artifacts, etc. The original source code for the game is not available. All I have is the executable and the data files that get installed with it. My job is to “excavate” that executable and all its data files, pick them apart and get them to reveal their secrets to me. Some of those data files may contain images used in the game, some audio, some information about the levels/maps… The executable contains the “logic” used to run the game probably. Things like what happens when an enemy touches the main player? How much does your score or health go down? What happens when your character dies?